Modsplan
- Modular Specification of Programming Languages
- Project Status
- Token Specifications
- Syntax Specifications
- Semantic Definitions
- Compiler
- Contact
Modular Specification of Programming Languages
Esk, of course, had not been trained, and it is well known that a vital ingredient of success is not knowing that what you're attempting can't be done.
—Terry Pratchett, Equal Rites, 1987
Modsplan is a language for writing specifications of programming languages (a meta-language). A Modsplan specification provides a formal definition of the syntax and semantics of a language. These specifications are modular: common definitions (for constants, expressions, statements, etc.) may be shared between languages.
Modsplan is designed to be readable by humans and computers. Programmers can use a Modsplan spec as a complete formal language reference. The Modsplan compiler reads the same specification in order to compile the defined language. (It is a universal compiler.) This guarantees that the implementation follows the specification (barring compiler bugs).
Modsplan uses three kinds of specifications to define a language:
- a
tokensgrammar specifies how characters of a source text are grouped into tokens; - a
syntaxgrammar defines the language syntax, based on tokens; - a
defn(definition) specifies code to generate for each syntactic element.
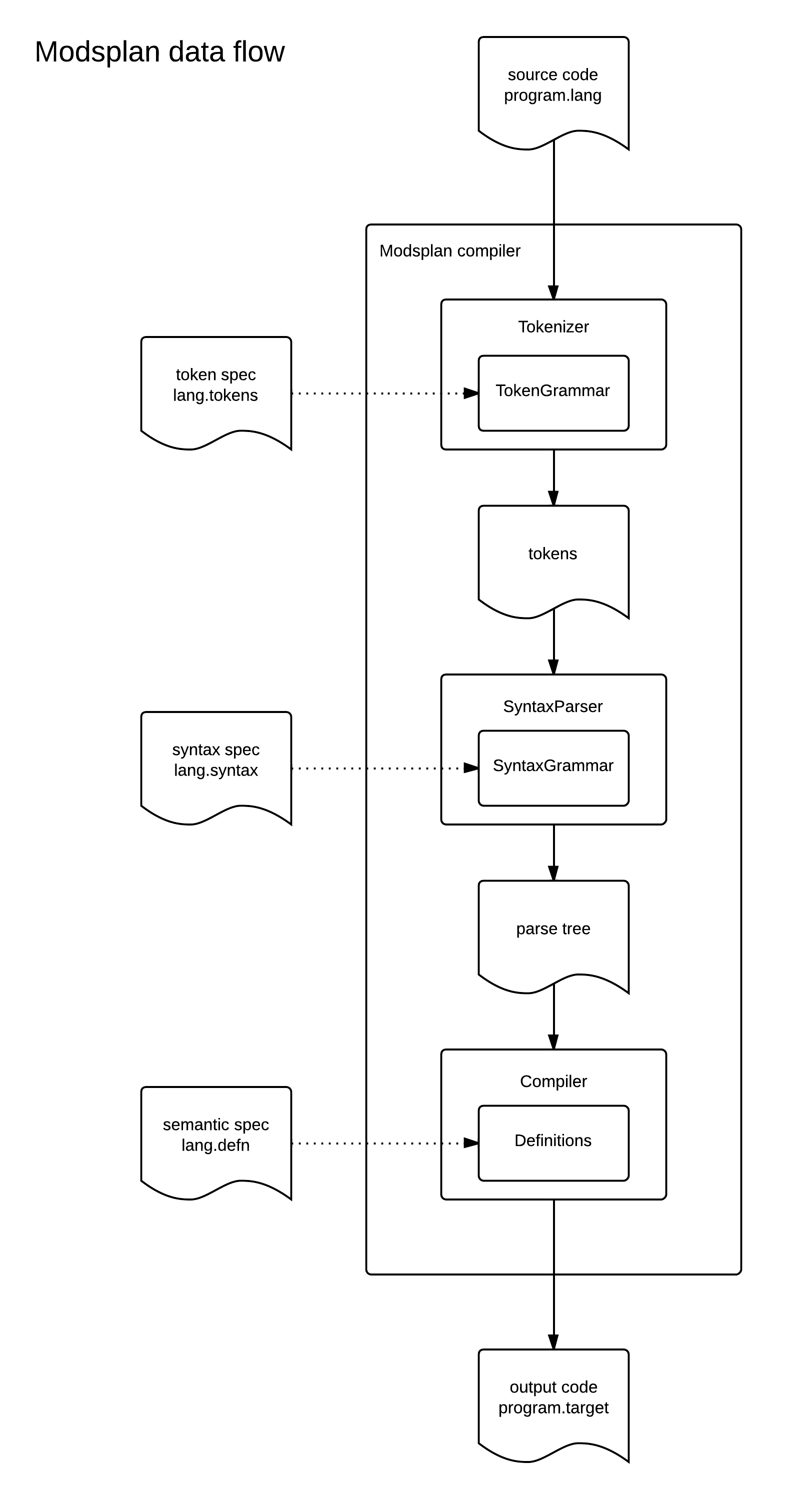
The data flow diagram illustrates how the Modsplan compiler processes source text using the three specifications. (Click diagram for PDF.)
Specification files are named for the language they define, so they can be automatically loaded by the compiler. (The extension of a source text filename names the language in which it is written.)
The grammar used in the tokens specs and syntax specs is a simple but powerful BNF variant. A defn spec is a list of definitions. Each definition specifies the target code instructions to generate for a parse tree node that matches a given signature.
Three simple meta-languages are used in Modsplan specifications to define a programming language: the Modsplan grammar notation, the Modsplan defn notation, and the target instruction set.
To generate code for many platforms, our defn specs typically target SBIL (a Stack-Based Intermediate Language created for this project), which will be translated to LLVM.
Project Status
The Tokenizer and Syntax Parser were developed in 2011. Code generation was implemented in 2013. Specifications have been written for a large subset of the C language, and a small statically-typed language with Python-like syntax. The compiler compiles test programs in these languages well. Modsplan is currently a research project; there is much work to be done before it may be useful as a production compiler.
In July 2014, this website was created, and Modsplan was
released on GitHub
with a GPL v2.0 license. See the ReadMe file there for a simple example.
Donations to support this project are gratefully accepted.
Token Specifications
The asteroid to kill this dinosaur is still in orbit.
—Lex Manual Page (see also dinosaur.compilertools.net)
The Modsplan Tokenizer reads characters from a source text, collecting them into strings, to output a sequence of tokens. The grouping of characters into tokens is directed by a token specification, loaded at startup. This is a text file named with a .tokens extension, containing a list of
grammar rules defining each kind of token in the source language. The names of the token kinds defined in the token specification are written in uppercase.
As the Tokenizer scans the source text, it chooses the token kind that matches the longest sequence of characters. (In case of a tie, the one defined first in the spec.) Each token that is output contains a token kind name and a string of characters from the source that matched its rule. When no match is found, a single character is output, with no name. (These are are typically punctuation characters.)
The rules of the token grammar may also define nonterminals that are not token kinds. These are denoted with lowercase names, and may be used to define tokens or other nonterminals.
An item on the right side of a token rule may be a (nontoken) nonterminal, a literal, or a character class.
- A literal is a string of characters in quotes, which must match the input characters exactly.
- A character class is a single uppercase letter:
Lmatches any lowercase letter,Uany uppercase letter,Dany decimal digit,Pany printable character (including a space).
base.metagrammar for details of the Modsplan grammars.
This token specification defines INTEGER and RELATION tokens:
INTEGER => D+ # one or more digit characters RELATION => '==' RELATION => '!=' RELATION => inequality '='? # inequality followed by optional '=' inequality => '<' inequality => '>'
Syntax Specifications
The Modsplan Syntax Parser reads tokens and produces a parse tree, guided by the rules of a syntax grammar. An item on the right side of a syntax rule may be a nonterminal, a literal, or a token name. Token names are defined in the tokens grammar, and used in the syntax grammar.
The following table shows the differences between the tokens grammar and syntax grammar. The metagrammars document the syntax of the Modsplan grammars.
| Grammar | tokenname | charclass | Documentation |
|---|---|---|---|
| tokens | Left side | Right side |
tokens.metagrammar |
| syntax | Right side | not used |
syntax.metagrammar |
| metagrammar | not used | Right side |
metagrammar.metagrammar |
The syntax of the metagrammars is documented in metagrammar.metagrammar, which is also its own metagrammar. The metagrammars are based on base.metagrammar, which is "imported" into each of them.
For modularity and reusability, all specifications (tokens, syntax, and defn) may import others of the same type. This is done with a use directive (see base.metagrammar). The rules of the imported file are processed at the location of the directive. (Circular imports are ignored.)
In the current implementation, imports are handled independently for each of the three specification types. This provides maximum flexibility, but has the drawback that a language "module" is not a coherent entity.
One nonterminal in the syntax specification loaded by the Parser must be marked with a .root suffix. (If more than one is marked root, the last is used.)
The Syntax Parser tries every alternate specified in the syntax grammar, choosing the parse that uses the most tokens. (If more than one parse uses the most tokens, an ambiguous parse error is shown, which may be suppressed with a compiler flag.)
This is part of a syntax specification for statements in the C language:
statement => if
statement => while
statement => compoundstatement
statement => expression ';'
if => 'if' '(' test ')' statement else?
else => 'else' statement
while => 'while' '(' test ')' statement
compoundstatement => '{' blockitem* '}'
blockitem => declaration ';'
blockitem => statement
Semantic Definitions
The defn specification is not a grammar, but a list of definitions. Each definition describes a node in a parse tree, its children, and the target code to generate for such a node. Starting at the root, the compiler examines a node of the parse tree. If it finds a definition matching this node, it generates the specified target instructions. This may involve compiling code for the children of the node, or using the text in them. If no definition is found matching a node, the compiler visits each of its children in order.
The syntax of defn specifications is specified in defn_grammar. (This grammar is actually loaded by the compiler to parse defn specifications. However, changes to the defn grammar may require changes to the compiler itself.)
This is a definition for an if statement:
if(test statement else?)
&test
'br' iftrue, iffalse
iftrue:
&statement
'br' ifend
iffalse:
&else?
ifend:
Compiler
Run python compiler.py to see command options for the compiler.
When the Modsplan compiler starts, it loads token, syntax, and defn specifications for the language of the given source text. (Language is determined by the extension of the source filename.) Then it tokenizes the source according to the token specification. The tokens are parsed according to the syntax specification, to create a parse tree. The parse tree is traversed to generate code, according to the defn specification. Errors at any point in the process are reported to the user, usually showing the location of the error.
Contact
Modsplan is a project of
![]()
Send email to Davi Post, the developer.